一、Logstash简介
(简介内容摘自网络)
1、官网
https://www.elastic.co/products/logstash
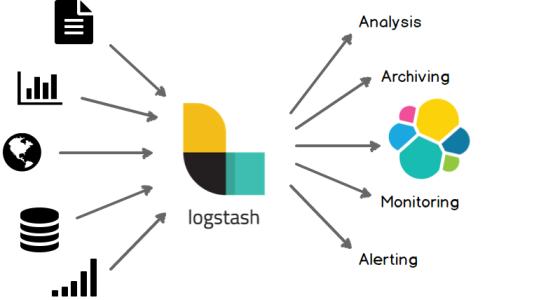
2、软件介绍
官方介绍:Logstash is an open source data collection engine with real-time pipelining capabilities。简单来说logstash就是一个具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
Logstash常用于日志关系系统中做日志采集设备;
Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
- inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
- filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
-
outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
其中inputs和outputs支持codecs(coder&decoder)在1.3.0 版之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入 期处理不同类型的数据,所以完整的数据流程应该是:input | decode | filter | encode | output;codec 的引入,使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如:graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等
二、Logstash安装部署
1.安装logstash程序包
方法一:RPM包安装方法
1.下载logstash RPM安装包
下载地址:https://www.elastic.co/downloads/logstash
下载程序包:logstash-7.9.1.rpm
安装
]# yum install logstash-7.9.1.rpm
方法二:YUM安装方法【推荐】
1.下载并安装公共签名密钥
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.yum源创建repo文件
~]# cat > /etc/yum.repos.d/elastic.repo << EOF
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
3.yum安装
]# sudo yum install logstash
2.配置环境变量
1.在/etc/profile.d目录中创建文件logstash.sh,并写入export PATH=/usr/share/logstash/bin:$PATH内容
]# cat > /etc/profile.d/logstash.sh << EOF
export PATH=/usr/share/logstash/bin:\$PATH
EOF
2.使其生效:
]# source /etc/profile.d/logstash.sh
3.查看是否生效:
]# echo $PATH
/usr/share/logstash/bin:/usr/share/logstash/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
3.安装java环境包【若没有jdk需要安装】
]# yum install java-11-openjdk
三、Logstash配置和使用
官方使用文档:https://www.elastic.co/guide/en/logstash/current/index.html
1.常用参数:
| 参数 | 说明 | 举例 |
|---|---|---|
| -e | 立即执行,使用命令行里的配置参数启动实例 | logstash -e ‘input {stdin {}} output {stdout {}}’ |
| -f | 指定启动实例的配置文件 | logstash -f config/test.conf |
| -t | 测试配置文件的正确性 | logstash-f config/test.conf -t |
| -l | 指定日志文件名称 | logstash-f config/test.conf -l logs/test.log |
| -w | 指定filter线程数量,默认线程数是5 | logstash-f config/test.conf -w 8 |
2.Logstash常用插件
1.input插件:
File: 从指定的文件中读取事件流(FileWatch监听文件的变化;.sincedb记录了每个被监听的文件的inode,major,number,minor,number,pos);
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | hash | {} | 用于向Event中添加字段 |
| close_older | number | 3600 | 设置文件多久秒内没有更新就关掉对文件的监听 |
| codec | string | “plain” | 输入数据之后对数据进行解码 |
| delimiter | string | “\n” | 文件内容的行分隔符,默认按照行进行Event封装 |
| discover_interval | number | 15 | 间隔多少秒查看一下path匹配对路径下是否有新文件产生 |
| enable_metric | boolean | true | |
| exclude | array | 无 | path匹配的文件中指定例外,如:path => “/var/log/“;exclude =>”.gz” |
| id | string | 无 | 区分两个相同类型的插件,比如两个filter,在使用Monitor API监控是可以区分,建议设置上ID |
| ignore_older | number | 无 | 忽略历史修改,如果设置3600秒,logstash只会发现一小时内被修改过的文件,一小时之前修改的文件的变化不会被读取,如果再次修改该文件,所有的变化都会被读取,默认被禁用 |
| max_open_files | number | 无 | logstash可以同时监控的文件个数(同时打开的file_handles个数),如果你需要处理多于这个数量多文件,可以使用“close_older”去关闭一些文件 |
| path | array | 无 | 必须设置项,用于匹配被监控的文件,如“/var/log/.log”或者“/var/log/*/*.log”,必须使用绝对路径 |
| sincedb_path | string | 无 | 文件读取记录,必须指定一个文件而不是目录,文件中保存没个被监控的文件等当前inode和byteoffset,默认存放位置“$HOME/.sincedb*” |
| sincedb_write_interval | number | 15 | 间隔多少秒写一次sincedb文件 |
| start_position | “beginning”,“end” | ” end” | 从文件等开头还是结尾读取文件内容,默认是结尾,如果需要导入文件中的老数据,可以设置为“beginning”,该选项只在第一次启动logstash时有效,如果文件已经存在于sincedb的记录内,则此配置无效 |
| stat_interval | number | 1 | 间隔多少秒检查一下文件是否被修改,加大此参数将降低系统负载,但是增加了发现新日志的间隔时间 |
| tags | array | 无 | 可以在Event中增加标签,以便于在后续的处理流程中使用 |
| type | string |
Event的type字段,如果采用elasticsearch做store,在默认情况下将作为elasticsearch 的type |
file使用实例:
1.在/etc/logstash/conf.d目录下创建文件fiels.conf,并写入如下内容:
input {
file {
path => ["/var/log/messages"]
type => "system"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug
}
}
2.设置/var/log/messages文件的访问权限
]# chmod 644 /var/log/messages
3.执行logstash开始测试,如下即以行的形式获取到messages的数据信息
]# logstash -f /etc/logstash/conf.d/fiels.conf
......
{
"@version" => "1",
"@timestamp" => 2020-09-23T02:17:40.973Z,
"path" => "/var/log/messages",
"type" => "system",
"message" => "Sep 23 10:17:02 master01 logstash: \"message\" => \"Sep 23 07:49:29 master01 kernel: SRAT: PXM 0 -> APIC 0x48 -> Node 0\",",
"host" => "master01"
}
......
udp: 通过udp协议从网络连接来读取Message,其必须参数为port,用于指明自己监听的端口,host则指明自己监听的IP地址;
udp使用示例:
实现目的:让另一个主机的日志收集工具(这里使用collectd演示)将日志数据通过udp协议传递到logstash的input插件中,logstash收集后进行输出。
1.下载epel源
[root@node02 ~]# yum install wget -y
]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
2.安装collectd
]# yum install collectd -y
3.配置collectd:在/etc/collectd.conf配置文件中配置如下选项项:
]# grep -v "^#" /etc/collectd.conf | grep -v "^$"
Hostname "node02"
LoadPlugin syslog
LoadPlugin cpu
LoadPlugin interface
LoadPlugin load
LoadPlugin memory
LoadPlugin network
<Plugin network>
<Server "192.168.239.130" "50051">
# 192.168.239.130是对应logstash主机的IP地址,50051是其监听的udp端口
</Server>
</Plugin>
4.启动collectd
]# systemctl start collectd
5.在logstash上创建配置文件:
]# more udp.conf
input {
udp {
port => 50051
codec => collectd {}
type => "colletcd"
}
}
output {
stdout {
codec => rubydebug
}
}
6.logstash运行udp配置文件
]# logstash -f /etc/logstash/conf.d/udp.conf
......
{
"plugin" => "interface",
"@version" => "1",
"plugin_instance" => "lo",
"rx" => 0,
"type" => "colletcd",
"@timestamp" => 2020-09-23T06:28:46.548Z,
"collectd_type" => "if_octets",
"tx" => 0,
"host" => "node02"
}
......
redis:从redis读取数据,支持redis channel和lists两种方式;
2.filter插件
用于在将event通过output发出之前对其实现某些处理功能。
grok:用于分析并结构化文本数据,目前是logstash中将非结构化日志转化为结构化可查询数据的最好选择。
自定义grok模式:
grok模式是基于正则表达式编写,其元字符与其它用到正则表达式的工具awk/sed/grep/pcre差别不大。
grok pattren的语法为:%{SYNTAX:semantic},”:” 前面是grok-pattrens中定义的变量,后面可以自定义变量的名称。(?:%{SYNTAX:semantic}|-)这种形式是条件判断。
如果有双引号””或者中括号[],需要加 \ 进行转义。
grok-patterns默认路径:/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
自定义NGINX的access.log日志的grok模式:
# nginx access log
NGUSERNAME [a-zA-Z\.\@\+_%]+
NGUSER %{NGUSERNAME}
NGINXACCESS %{IPORHOST:clientip} - %{NOTSPACE:remote_user} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}
配置文件:
input {
file {
path => "/var/log/nginx/access.log"
type => "nginxaccess"
start_position => "beginning"
}
}
filter {
grok {
patterns_dir => "/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patter
ns/grok-patterns"
match => { "message" => "%{NGINXACCESS}" }
}
}
output {
stdout {
codec => rubydebug
}
}
输出结果:
{
"message" => "192.168.239.1 - - [25/Sep/2020:18:13:41 +0800] \"GET / HTTP/1.1\" 304 0 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36\" \"-\"",
"host" => "master01",
"remote_user" => "-",
"path" => "/var/log/nginx/access.log",
"bytes" => "0",
"httpversion" => "1.1",
"http_x_forwarded_for" => "\"-\"",
"@timestamp" => 2020-09-25T10:14:06.088Z,
"agent" => "\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36\"",
"timestamp" => "25/Sep/2020:18:13:41 +0800",
"response" => "304",
"type" => "nginxaccess",
"referrer" => "\"-\"",
"clientip" => "192.168.239.1",
"request" => "/",
"verb" => "GET",
"@version" => "1"
}
未完待续……




评论前必须登录!
注册