1. 下载anaconda程序包
点击这里开始下载
2.打开anaconda UI界面
可以看到默认base环境,显示本机已安装的一些程序,如下截图
3.安装scrapy
点击这里达到scrapy官网
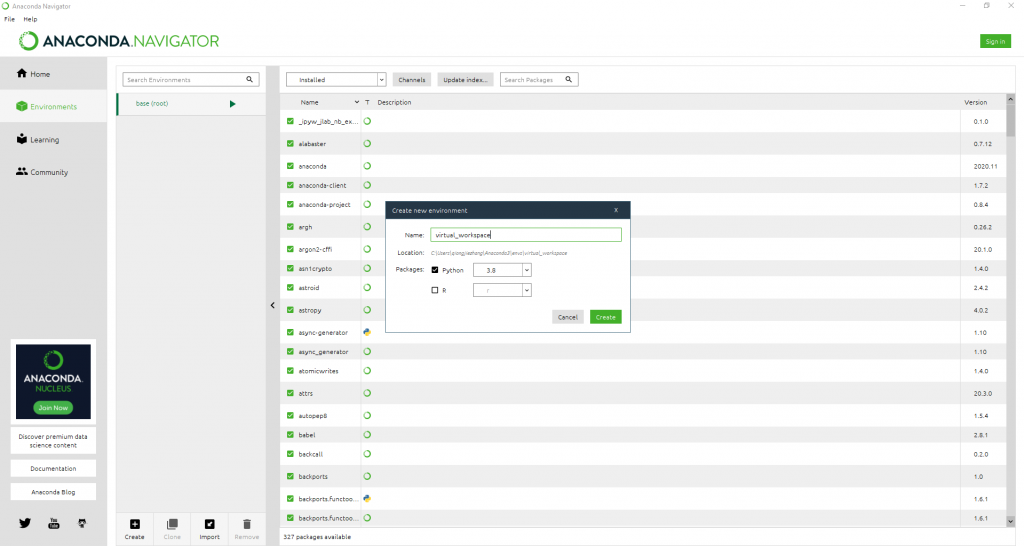
为了方便区分,我们可以自定义创建一个environment,如下:
回到anaconda界面,运行刚才创建的virtual_workspace环境,输入以下命令开始安装相关程序包:
conda install -c conda-forge scrapy pylint autopep8 ipython protego -y
查看scrapy版本:
(virtual_workspace) C:\Users\Kevin>scrapy
Scrapy 2.4.1 - no active project
4.scrapy基础命令
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
以上命令可以参考注释信息,尝试在终端窗口输入测试输出结果。
startproject命令可以直接创建一个空的项目,而且会自动创建必要的文件,详细使用说明如下:
(virtual_workspace) C:\Users\Kevin>scrapy startproject
Usage
=====
scrapy startproject <project_name> [project_dir]
Create new project
Options
=======
--help, -h show this help message and exit
Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
shell命令
(virtual_workspace) C:\Users\qiongjiezhang\projects\worldmeters>scrapy shell -h
Usage
=====
scrapy shell [url|file]
Interactive console for scraping the given url or file. Use ./file.html syntax
or full path for local file.
Options
=======
--help, -h show this help message and exit
-c CODE evaluate the code in the shell, print the result and
exit
--spider=SPIDER use this spider
--no-redirect do not handle HTTP 3xx status codes and print response
as-is
Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
输入命令:scrayp shell可以进入scrapy交互控制台,然后可以按需键入相关命令进行数据探索。
cls:此命令可以,清除当前终端内容,回到顶部
5.实例演示
1.创建目录projects,并在此目录下创建project
(virtual_workspace) C:\Users\Kevin>mkdir projects
(virtual_workspace) C:\Users\Kevin>cd projects
(virtual_workspace) C:\Users\Kevin\projects>scrapy startproject worldmeters
New Scrapy project 'worldmeters', using template directory 'C:\Users\Kevin\anaconda3\envs\virtual_workspace\lib\site-packages\scrapy\templates\project', created in:
C:\Users\Kevin\projects\worldmeters
You can start your first spider with:
cd worldmeters
scrapy genspider example example.com
此时就会在目录C:\Users\Kevin\projects\worldmeters下面生成worldmeters子目录,里面包含了默认的必要文件。
默认生成的几个重要文件及其作用:
- scrapy.cfg:包含了默认配置和部署位置相关的信息;
- __init__.py:空文件
- items.py:使用它来清理我们爬取的数据,并对数据进行分类和存储
- middlewares.py:请求和相应数据
- pipelines.py:存储爬取的数据到数据库存储
- settings.py:配置此项目的配置信息
2.按照提示命令自动生成对应的scrapy文件(这里以世界著名统计网站为例进行演示获取中国人口等数据):
(virtual_workspace) C:\Users\Kevin\projects>cd worldmeters
(virtual_workspace) C:\Users\Kevin\projects\worldmeters>scrapy genspider countries https://www.worldometers.info/world-population/china-population/
如上命令,进入对应的project,输入提示的命令countries是我们为scrapy自定义的名字,url尾部“/”去掉,因为scrapy默认使用http协议,所以更改后的命令参考如下:
(virtual_workspace) C:\Users\Kevin\projects>cd worldmeters
(virtual_workspace) C:\Users\Kevin\projects\worldmeters>scrapy genspider countries www.worldometers.info/world-population/population-by-country
Created spider 'countries' using template 'basic' in module:
worldmeters.spiders.countries
此时在project目录会对应地生成一个名为countries.py的python文件,此文件内容如下:
import scrapy
class CountriesSpider(scrapy.Spider):
name = 'countries'
allowed_domains = ['www.worldometers.info/world-population/population-by-country']
start_urls = ['http://www.worldometers.info/world-population/population-by-country/']
def parse(self, response):
pass
这里我们需要更改”allowed_domains”和”start_urls”,更改后如下所示:
import scrapy
class CountriesSpider(scrapy.Spider):
name = 'countries'
allowed_domains = ['www.worldometers.info/']
start_urls = ['https://www.worldometers.info/world-population/population-by-country/']
def parse(self, response):
pass
3.输入命令scrapy shell进入scrapy的交互控制台
然后输入如下基础命令即可以对web网站进行craw相关信息了,如下操作可以获取对应网址的body信息。view(response)命令可以打开对应网站的窗口。
xpath使用示例:
In [1]: r = scrapy.Request(url="https://www.worldometers.info/world-population/population-by-country/")
In [2]: fetch(r)
2021-04-26 09:08:21 [scrapy.core.engine] INFO: Spider opened
2021-04-26 09:08:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.worldometers.info/world-population/population-by-country/> (referer: None)
In [3]: title = response.xpath("//h1")
In [4]: title
Out[4]: [<Selector xpath='//h1' data='<h1>Countries in the world by populat...'>]
In [5]: title.get()
Out[5]: '<h1>Countries in the world by population (2021)</h1>'
In [6]: title = response.xpath("//h1/text()")
In [7]: title.get()
Out[7]: 'Countries in the world by population (2021)'
In [9]: countries = response.xpath("//td/a/text()")
In [10]: countries.get()
Out[10]: 'China'
In [11]: countries.getall()
Out[11]:
['China',
'India',
'United States',
'Indonesia',
'Pakistan',
'Brazil',
'Nigeria',
'Bangladesh',
'Russia',
'Mexico',
'Japan',
'Ethiopia',
'Philippines',
'Egypt',
'Vietnam',
'DR Congo',
'Turkey',
'Iran',
'Germany',
'Thailand',
'United Kingdom',
'France',
'Italy',
'Tanzania',
'South Africa',
'Myanmar',
'Kenya',
'South Korea',
'Colombia',
'Spain',
'Uganda',
'Argentina',
'Algeria',
'Sudan',
'Ukraine',
'Iraq',
'Afghanistan',
'Poland',
'Canada',
'Morocco',
'Saudi Arabia',
'Uzbekistan',
'Peru',
'Angola',
'Malaysia',
'Mozambique',
'Ghana',
'Yemen',
'Nepal',
'Venezuela',
'Madagascar',
'Cameroon',
"Côte d'Ivoire",
'North Korea',
'Australia',
'Niger',
'Taiwan',
'Sri Lanka',
'Burkina Faso',
'Mali',
'Romania',
'Malawi',
'Chile',
'Kazakhstan',
'Zambia',
'Guatemala',
'Ecuador',
'Syria',
'Netherlands',
'Senegal',
'Cambodia',
'Chad',
'Somalia',
'Zimbabwe',
'Guinea',
'Rwanda',
'Benin',
'Burundi',
'Tunisia',
'Bolivia',
'Belgium',
'Haiti',
'Cuba',
'South Sudan',
'Dominican Republic',
'Czech Republic (Czechia)',
'Greece',
'Jordan',
'Portugal',
'Azerbaijan',
'Sweden',
'Honduras',
'United Arab Emirates',
'Hungary',
'Tajikistan',
'Belarus',
'Austria',
'Papua New Guinea',
'Serbia',
'Israel',
'Switzerland',
'Togo',
'Sierra Leone',
'Hong Kong',
'Laos',
'Paraguay',
'Bulgaria',
'Libya',
'Lebanon',
'Nicaragua',
'Kyrgyzstan',
'El Salvador',
'Turkmenistan',
'Singapore',
'Denmark',
'Finland',
'Congo',
'Slovakia',
'Norway',
'Oman',
'State of Palestine',
'Costa Rica',
'Liberia',
'Ireland',
'Central African Republic',
'New Zealand',
'Mauritania',
'Panama',
'Kuwait',
'Croatia',
'Moldova',
'Georgia',
'Eritrea',
'Uruguay',
'Bosnia and Herzegovina',
'Mongolia',
'Armenia',
'Jamaica',
'Qatar',
'Albania',
'Puerto Rico',
'Lithuania',
'Namibia',
'Gambia',
'Botswana',
'Gabon',
'Lesotho',
'North Macedonia',
'Slovenia',
'Guinea-Bissau',
'Latvia',
'Bahrain',
'Equatorial Guinea',
'Trinidad and Tobago',
'Estonia',
'Timor-Leste',
'Mauritius',
'Cyprus',
'Eswatini',
'Djibouti',
'Fiji',
'Réunion',
'Comoros',
'Guyana',
'Bhutan',
'Solomon Islands',
'Macao',
'Montenegro',
'Luxembourg',
'Western Sahara',
'Suriname',
'Cabo Verde',
'Micronesia',
'Maldives',
'Malta',
'Brunei ',
'Guadeloupe',
'Belize',
'Bahamas',
'Martinique',
'Iceland',
'Vanuatu',
'French Guiana',
'Barbados',
'New Caledonia',
'French Polynesia',
'Mayotte',
'Sao Tome & Principe',
'Samoa',
'Saint Lucia',
'Channel Islands',
'Guam',
'Curaçao',
'Kiribati',
'Grenada',
'St. Vincent & Grenadines',
'Aruba',
'Tonga',
'U.S. Virgin Islands',
'Seychelles',
'Antigua and Barbuda',
'Isle of Man',
'Andorra',
'Dominica',
'Cayman Islands',
'Bermuda',
'Marshall Islands',
'Northern Mariana Islands',
'Greenland',
'American Samoa',
'Saint Kitts & Nevis',
'Faeroe Islands',
'Sint Maarten',
'Monaco',
'Turks and Caicos',
'Saint Martin',
'Liechtenstein',
'San Marino',
'Gibraltar',
'British Virgin Islands',
'Caribbean Netherlands',
'Palau',
'Cook Islands',
'Anguilla',
'Tuvalu',
'Wallis & Futuna',
'Nauru',
'Saint Barthelemy',
'Saint Helena',
'Saint Pierre & Miquelon',
'Montserrat',
'Falkland Islands',
'Niue',
'Tokelau',
'Holy See']
css选择器示例:
In [1]: r = scrapy.Request(url="https://www.worldometers.info/world-population/population-by-country/")
In [2]: fetch(r)
2021-04-26 09:15:23 [scrapy.core.engine] INFO: Spider opened
2021-04-26 09:15:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.worldometers.info/world-population/population-by-country/> (referer: None)
In [3]: title_css = response.css("h1::text")
In [4]: title_css.get()
Out[4]: 'Countries in the world by population (2021)'
In [5]: countries_css = response.css("td a::text").getall()
In [6]: countries_css
Out[6]:
['China',
'India',
'United States',
'Indonesia',
'Pakistan',
'Brazil',
'Nigeria',
'Bangladesh',
'Russia',
'Mexico',
'Japan',
'Ethiopia',
'Philippines',
'Egypt',
'Vietnam',
'DR Congo',
'Turkey',
'Iran',
'Germany',
'Thailand',
'United Kingdom',
'France',
'Italy',
'Tanzania',
'South Africa',
'Myanmar',
'Kenya',
'South Korea',
'Colombia',
'Spain',
'Uganda',
'Argentina',
'Algeria',
'Sudan',
'Ukraine',
'Iraq',
'Afghanistan',
'Poland',
'Canada',
'Morocco',
'Saudi Arabia',
'Uzbekistan',
'Peru',
'Angola',
'Malaysia',
'Mozambique',
'Ghana',
'Yemen',
'Nepal',
'Venezuela',
'Madagascar',
'Cameroon',
"Côte d'Ivoire",
'North Korea',
'Australia',
'Niger',
'Taiwan',
'Sri Lanka',
'Burkina Faso',
'Mali',
'Romania',
'Malawi',
'Chile',
'Kazakhstan',
'Zambia',
'Guatemala',
'Ecuador',
'Syria',
'Netherlands',
'Senegal',
'Cambodia',
'Chad',
'Somalia',
'Zimbabwe',
'Guinea',
'Rwanda',
'Benin',
'Burundi',
'Tunisia',
'Bolivia',
'Belgium',
'Haiti',
'Cuba',
'South Sudan',
'Dominican Republic',
'Czech Republic (Czechia)',
'Greece',
'Jordan',
'Portugal',
'Azerbaijan',
'Sweden',
'Honduras',
'United Arab Emirates',
'Hungary',
'Tajikistan',
'Belarus',
'Austria',
'Papua New Guinea',
'Serbia',
'Israel',
'Switzerland',
'Togo',
'Sierra Leone',
'Hong Kong',
'Laos',
'Paraguay',
'Bulgaria',
'Libya',
'Lebanon',
'Nicaragua',
'Kyrgyzstan',
'El Salvador',
'Turkmenistan',
'Singapore',
'Denmark',
'Finland',
'Congo',
'Slovakia',
'Norway',
'Oman',
'State of Palestine',
'Costa Rica',
'Liberia',
'Ireland',
'Central African Republic',
'New Zealand',
'Mauritania',
'Panama',
'Kuwait',
'Croatia',
'Moldova',
'Georgia',
'Eritrea',
'Uruguay',
'Bosnia and Herzegovina',
'Mongolia',
'Armenia',
'Jamaica',
'Qatar',
'Albania',
'Puerto Rico',
'Lithuania',
'Namibia',
'Gambia',
'Botswana',
'Gabon',
'Lesotho',
'North Macedonia',
'Slovenia',
'Guinea-Bissau',
'Latvia',
'Bahrain',
'Equatorial Guinea',
'Trinidad and Tobago',
'Estonia',
'Timor-Leste',
'Mauritius',
'Cyprus',
'Eswatini',
'Djibouti',
'Fiji',
'Réunion',
'Comoros',
'Guyana',
'Bhutan',
'Solomon Islands',
'Macao',
'Montenegro',
'Luxembourg',
'Western Sahara',
'Suriname',
'Cabo Verde',
'Micronesia',
'Maldives',
'Malta',
'Brunei ',
'Guadeloupe',
'Belize',
'Bahamas',
'Martinique',
'Iceland',
'Vanuatu',
'French Guiana',
'Barbados',
'New Caledonia',
'French Polynesia',
'Mayotte',
'Sao Tome & Principe',
'Samoa',
'Saint Lucia',
'Channel Islands',
'Guam',
'Curaçao',
'Kiribati',
'Grenada',
'St. Vincent & Grenadines',
'Aruba',
'Tonga',
'U.S. Virgin Islands',
'Seychelles',
'Antigua and Barbuda',
'Isle of Man',
'Andorra',
'Dominica',
'Cayman Islands',
'Bermuda',
'Marshall Islands',
'Northern Mariana Islands',
'Greenland',
'American Samoa',
'Saint Kitts & Nevis',
'Faeroe Islands',
'Sint Maarten',
'Monaco',
'Turks and Caicos',
'Saint Martin',
'Liechtenstein',
'San Marino',
'Gibraltar',
'British Virgin Islands',
'Caribbean Netherlands',
'Palau',
'Cook Islands',
'Anguilla',
'Tuvalu',
'Wallis & Futuna',
'Nauru',
'Saint Barthelemy',
'Saint Helena',
'Saint Pierre & Miquelon',
'Montserrat',
'Falkland Islands',
'Niue',
'Tokelau',
'Holy See']
scrapy crawl命令(注意:此命令需要在文件scrapy.cfg 的同级目录执行)
编辑countries.py文件,如下:
import scrapy
class CountriesSpider(scrapy.Spider):
name = 'countries'
allowed_domains = ['www.worldometers.info/']
start_urls = ['https://www.worldometers.info/world-population/population-by-country/']
def parse(self, response):
title = response.xpath("//h1/text()").get()
cities = response.xpath("//td/a/text()").getall()
yield {
'title': title,
'cities': cities
}
执行此命令后返回结果如下:
(base) [root@ip-172-31-13-197 worldomethers]# scrapy crawl countries
2021-04-27 03:00:35 [scrapy.utils.log] INFO: Scrapy 2.4.1 started (bot: worldomethers)
2021-04-27 03:00:35 [scrapy.utils.log] INFO: Versions: lxml 4.6.1.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.2.0, Python 3.8.5 (default, Sep 4 2020, 07:30:14) - [GCC 7.3.0], pyOpenSSL 19.1.0 (OpenSSL 1.1.1h 22 Sep 2020), cryptography 3.1.1, Platform Linux-4.14.225-121.357.amzn1.x86_64-x86_64-with-glibc2.10
2021-04-27 03:00:35 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor
2021-04-27 03:00:35 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'worldomethers',
'NEWSPIDER_MODULE': 'worldomethers.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['worldomethers.spiders']}
2021-04-27 03:00:35 [scrapy.extensions.telnet] INFO: Telnet Password: 7f0c1718df6f4fd3
2021-04-27 03:00:35 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2021-04-27 03:00:35 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2021-04-27 03:00:35 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2021-04-27 03:00:35 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2021-04-27 03:00:35 [scrapy.core.engine] INFO: Spider opened
2021-04-27 03:00:35 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2021-04-27 03:00:35 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-04-27 03:00:35 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://www.worldometers.info/robots.txt> (referer: None)
2021-04-27 03:00:35 [protego] DEBUG: Rule at line 2 without any user agent to enforce it on.
2021-04-27 03:00:35 [protego] DEBUG: Rule at line 10 without any user agent to enforce it on.
2021-04-27 03:00:35 [protego] DEBUG: Rule at line 12 without any user agent to enforce it on.
2021-04-27 03:00:35 [protego] DEBUG: Rule at line 14 without any user agent to enforce it on.
2021-04-27 03:00:35 [protego] DEBUG: Rule at line 16 without any user agent to enforce it on.
2021-04-27 03:00:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.worldometers.info/world-population/population-by-country/> (referer: None)
2021-04-27 03:00:35 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.worldometers.info/world-population/population-by-country/>
{'title': 'Countries in the world by population (2021)', 'cities': ['China', 'India', 'United States', 'Indonesia', 'Pakistan', 'Brazil', 'Nigeria', 'Bangladesh', 'Russia', 'Mexico', 'Japan', 'Ethiopia', 'Philippines', 'Egypt', 'Vietnam', 'DR Congo', 'Turkey', 'Iran', 'Germany', 'Thailand', 'United Kingdom', 'France', 'Italy', 'Tanzania', 'South Africa', 'Myanmar', 'Kenya', 'South Korea', 'Colombia', 'Spain', 'Uganda', 'Argentina', 'Algeria', 'Sudan', 'Ukraine', 'Iraq', 'Afghanistan', 'Poland', 'Canada', 'Morocco', 'Saudi Arabia', 'Uzbekistan', 'Peru', 'Angola', 'Malaysia', 'Mozambique', 'Ghana', 'Yemen', 'Nepal', 'Venezuela', 'Madagascar', 'Cameroon', "Côte d'Ivoire", 'North Korea', 'Australia', 'Niger', 'Taiwan', 'Sri Lanka', 'Burkina Faso', 'Mali', 'Romania', 'Malawi', 'Chile', 'Kazakhstan', 'Zambia', 'Guatemala', 'Ecuador', 'Syria', 'Netherlands', 'Senegal', 'Cambodia', 'Chad', 'Somalia', 'Zimbabwe', 'Guinea', 'Rwanda', 'Benin', 'Burundi', 'Tunisia', 'Bolivia', 'Belgium', 'Haiti', 'Cuba', 'South Sudan', 'Dominican Republic', 'Czech Republic (Czechia)', 'Greece', 'Jordan', 'Portugal', 'Azerbaijan', 'Sweden', 'Honduras', 'United Arab Emirates', 'Hungary', 'Tajikistan', 'Belarus', 'Austria', 'Papua New Guinea', 'Serbia', 'Israel', 'Switzerland', 'Togo', 'Sierra Leone', 'Hong Kong', 'Laos', 'Paraguay', 'Bulgaria', 'Libya', 'Lebanon', 'Nicaragua', 'Kyrgyzstan', 'El Salvador', 'Turkmenistan', 'Singapore', 'Denmark', 'Finland', 'Congo', 'Slovakia', 'Norway', 'Oman', 'State of Palestine', 'Costa Rica', 'Liberia', 'Ireland', 'Central African Republic', 'New Zealand', 'Mauritania', 'Panama', 'Kuwait', 'Croatia', 'Moldova', 'Georgia', 'Eritrea', 'Uruguay', 'Bosnia and Herzegovina', 'Mongolia', 'Armenia', 'Jamaica', 'Qatar', 'Albania', 'Puerto Rico', 'Lithuania', 'Namibia', 'Gambia', 'Botswana', 'Gabon', 'Lesotho', 'North Macedonia', 'Slovenia', 'Guinea-Bissau', 'Latvia', 'Bahrain', 'Equatorial Guinea', 'Trinidad and Tobago', 'Estonia', 'Timor-Leste', 'Mauritius', 'Cyprus', 'Eswatini', 'Djibouti', 'Fiji', 'Réunion', 'Comoros', 'Guyana', 'Bhutan', 'Solomon Islands', 'Macao', 'Montenegro', 'Luxembourg', 'Western Sahara', 'Suriname', 'Cabo Verde', 'Micronesia', 'Maldives', 'Malta', 'Brunei ', 'Guadeloupe', 'Belize', 'Bahamas', 'Martinique', 'Iceland', 'Vanuatu', 'French Guiana', 'Barbados', 'New Caledonia', 'French Polynesia', 'Mayotte', 'Sao Tome & Principe', 'Samoa', 'Saint Lucia', 'Channel Islands', 'Guam', 'Curaçao', 'Kiribati', 'Grenada', 'St. Vincent & Grenadines', 'Aruba', 'Tonga', 'U.S. Virgin Islands', 'Seychelles', 'Antigua and Barbuda', 'Isle of Man', 'Andorra', 'Dominica', 'Cayman Islands', 'Bermuda', 'Marshall Islands', 'Northern Mariana Islands', 'Greenland', 'American Samoa', 'Saint Kitts & Nevis', 'Faeroe Islands', 'Sint Maarten', 'Monaco', 'Turks and Caicos', 'Saint Martin', 'Liechtenstein', 'San Marino', 'Gibraltar', 'British Virgin Islands', 'Caribbean Netherlands', 'Palau', 'Cook Islands', 'Anguilla', 'Tuvalu', 'Wallis & Futuna', 'Nauru', 'Saint Barthelemy', 'Saint Helena', 'Saint Pierre & Miquelon', 'Montserrat', 'Falkland Islands', 'Niue', 'Tokelau', 'Holy See']}
2021-04-27 03:00:35 [scrapy.core.engine] INFO: Closing spider (finished)
2021-04-27 03:00:35 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 561,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 17174,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/404': 1,
'elapsed_time_seconds': 0.268398,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 4, 27, 3, 0, 35, 726264),
'item_scraped_count': 1,
'log_count/DEBUG': 8,
'log_count/INFO': 10,
'memusage/max': 55316480,
'memusage/startup': 55316480,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2021, 4, 27, 3, 0, 35, 457866)}
2021-04-27 03:00:35 [scrapy.core.engine] INFO: Spider closed (finished)
![Python 问题解决 | urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed-琼杰笔记](https://www.zhangqiongjie.com/wp-content/uploads/2020/02/python2-220x150.jpg)




评论前必须登录!
注册