一、简介
xpath,全程为xml path language。
两个可视化测试xpath和css语法的网站:
- https://try.jsoup.org/
- https://scrapinghub.github.io/xpath-playground/
二、演示
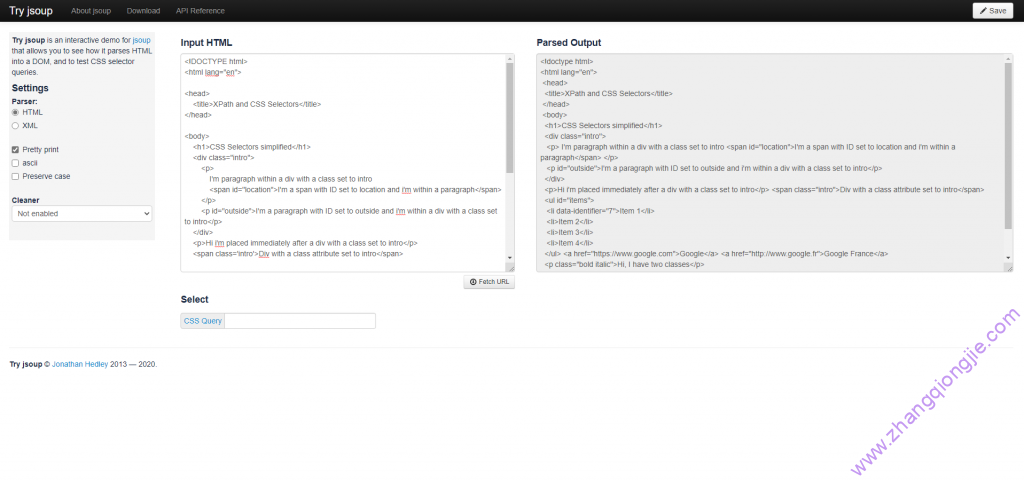
1. Html演示demo
点击 这里code-xpath 下载demo
2. 语法测试网站
点击 这里 打开xpath在线语法测试网站,将上面的demo复制到input输入框中,准备开始测试。
3.常用语法示例:
- //,后面跟标签名字,可以获取对应标签内容;
- [],中括号里面可以加条件进行选择,如//div[@class=”intro”],可以获取class的ID为intro的div的内容;
- /,可以从获取的标签内容中选择对应的内容,如//div[@class=”intro”]/p,获取指定内容的p标签的内容;
- or,可以获取多个标签内容,如//div[@class=”intro” or @class=”outro”]/p,获取class的ID为intro和outro的div标签中的所有p标签;
- text(),只获取标签中的内容,不包含标签,如//div[@class=”intro” or @class=”outro”]/p/text()
- @,获取标签内容元素的值,如//a/@href
- starts-with(),获取标签中以某字符开头的内容,如//a[starts-with(@href,”https”)],可以获取到a标签中href以https开头的内容;
- ends-with(),获取标签中中以fr结尾的内容,如//a[ends-with(@href,”fr”)]
- contains(),获取标签中包含某字符的内容,如 //a[contains(@href,”fr”)]
- 获取标签值包含某字符的内容,如//a[contains(text(),”France”)];
- 列表,获取标签列表中的某个元素
- 如//ul[@id=”items”]/li[1],可以获取id为items的ul标签中第1个li元素;
- 如//ul[@id=”items”]/li[1 or 4],可以获取id为items的ul标签中第1个到第4个li元素
- postions(),如//ul[@id=”items”]/li[position() = 1 or position() =4],可以获取id为items的ul标签中第1个和第4个li元素;
- latest(),如//ul[@id=”items”]/li[position() = 1 or position() = last()],可以获取id为items的ul标签中第1个和最后1个li元素;
- >,>=,<=,!=,算数运算符,如//ul[@id=”items”]/li[position() >=2],可以获取列表顺序大于等于2的li元素
- parent::,通过子标签获取父标签,如//p[@id=”unique”]/parent::div,表示获取id为unique的p标签的父div标签;
- node(),表示获取父标签,如//p[@id=”unique”]/parent::node()
- ancestor::,获取父目录的父目录,如//p[@id=”unique”]/ancestor::node()
- ancestor-or-self::,获取父目录的父目录和本标签//p[@id=”unique”]/ancestor-or-self::node()
- preceding::,获取之前的标签及内容,不包含父级标签,如//p[@id=’unique’]/preceding::node(),也可以在preceding::后面加上其他标签从获取的内容中进行过滤
- preceding-sibling::,获取之前同级标签及内容,如//p[@id=”outside”]/preceding-sibling::node()
- child::,获取子标签,如//div[@class=”intro”]/child::node()
- following::,获取之后的标签,如//div[@class=”intro”]/following::node()
注意:本站少数资源收集于网络,如涉及版权等问题请及时与站长联系,我们会在第一时间内与您协商解决。如非特殊说明,本站所有资源解压密码均为:zhangqiongjie.com。
作者:1923002089


![Python 问题解决 | urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed-琼杰笔记](https://www.zhangqiongjie.com/wp-content/uploads/2020/02/python2-220x150.jpg)


评论前必须登录!
注册