一、简述
通过使用css来对web网站进行筛选,过滤出我们想要爬取的内容,这里是一个示例代码html文件,为下面演示使用(可点击 这里 这里code 免费下载)
二、css基础使用演示
1.web工具
点击 这里 打开网页,复制演示代码中的html文件至”input html”选项框内,如下图所示
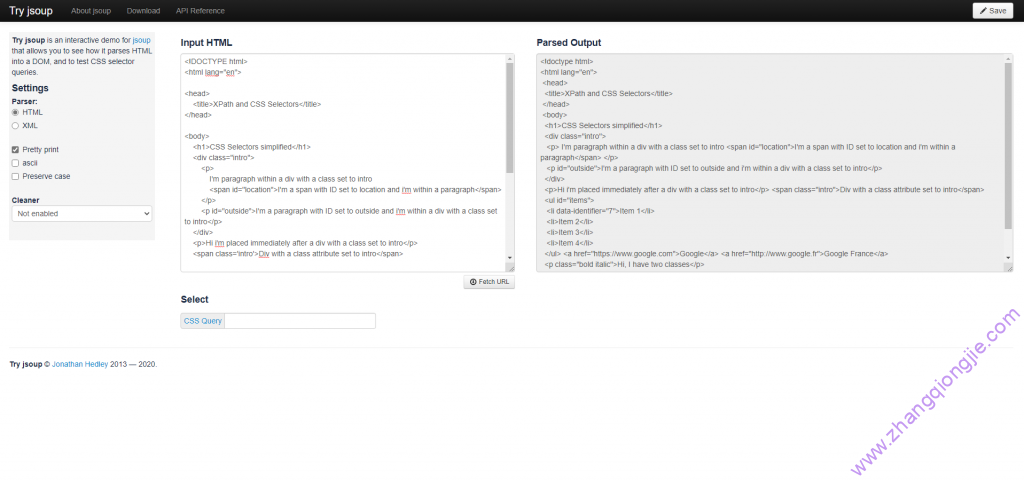
这里可以通过 ‘CSS Query’ 复选框来键入不同的标签值或者标签表达式,来匹配我们想要得到的内容。
2.基础表达式
下面是基础语法使用方法示例(官方语法示例点击 这里 查看):
- 标签名:直接键入标签名,如head,body,div,p,li等等,即可得到具有此标签的所有内容;
- class:点号加class的值,如”.intro”,可以显示所有相同ID的class的标签的内容;
- ID:”#”加ID值,如”#location”,可以显示ID值为location的内容,一般ID在一个html具有唯一性;
- 组合表达式:
- 标签名加”.”加class名,如”div.intro”;
- 标签名加”#”加ID值,如”span#location”;
- “.”加class加”.”加class,如”.bold.italic”;
- 从选定的标签中再获取相应的内容,如”div.intro p#outside”, 先选定了class为intro的div,然后中间加空格,后面继续跟表达式;
- 从选定的标签中再获取具有同一类标签的所有内容,可以使用大于号,如”div.intro > p”;
- 只获取选定标签中的某个没有class和ID的标签,可以使用加号,如”div.intro + p”;
- 列表:
- 从列表中选择某个内容,如”li[data-identifier=”7″]” 或 “[data-identifier=7]”;
- 从列表选择某个内容,也可以用公式nth-child()来选择某个值, 如”li:nth-child(1)”
- 获取列表奇数项:nth-child(odd),如”li:nth-child(odd)”;
- 获取列表偶数项:nth-child(even),如”li:nth-child(even)”
- 条件表达式:
- 以某字符开头的内容,如”a[href^=https]”;
- 以某字符结尾的内容,如”a[href$=fr]”;
- 获取包含某字符的内容,如”a[href*=google]” 或者 “a[href~=fr]”;
- 指定标签中包含指定标签,如”div ~ p”;



![Python 问题解决 | urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed-琼杰笔记](https://www.zhangqiongjie.com/wp-content/uploads/2020/02/python2-220x150.jpg)


评论前必须登录!
注册